I have aggregated some of the notable papers released recently, esp. ICLR 2021 submissions, with concise summaries, visualizations and my comments. The development in each field is summarized, and the future trends are speculated.
Caveats: I have omitted some very well-known recent papers such as GPT-3, as most readers should be adequately familiar with them. Admittedly, the coverage is far from exhaustive with heavy bias toward the areas of my interest (e.g. language models), and the amount of details I have written varies by papers.
Table of Contents with Summary & Conclusion
General Scaling Method
Summary:
- We now have better understanding of scaling of models in various domains and better tools for scaling, especially for conditional computations, memory saver and model parallelism.
Contents:
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- Scalable conditional computation!
- Training Large Neural Networks with Constant Memory using a New Execution Algorithm
- Proposes L2L, with which GPU/TPU memory usage becomes constant w.r.t. the number of layers.
- DeepSpeed
- A library with various tools for large-scale training, including L2L-like memory-saver and efficient block-sparse kernel
Future Trends:
- Improvement in conditional computation may allow conditional computation of not only FFN but also other dimensions of Transformer.
NLP
Summary:
- NLP is enjoying the improvement in not only scaling methods but also retrieval, efficient attention and various other techniques.
Contents:
- Retrieval-based approach:
- Pre-training via Paraphrasing
- Joint training of a retriever and a language model on retrieved similar texts as a replacement to MLM.
- Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval
- SotA multi-hop open-domain QA.
- Cross-lingual Retrieval for Iterative Self-Supervised Training
- SotA unsupervised multilingual translation
- Pre-training via Paraphrasing
- Efficient attention:
- Long Range Arena: A Benchmark for Efficient Transformers
- Which Transformer variant to use?
- Rethinking Attention with Performers
- SotA efficient attention
- Long Range Arena: A Benchmark for Efficient Transformers
- Others:
- Scaling Laws for Neural Language Models
- Finds an optimal allocation of computes to model size, batch size and iteration count based on the observed robust power law.
- Learning to Summarize From Human Feedback
- Fine-tuning a pre-trained LM with a RL objective shows a promising result.
- Measuring Massive Multitask Language Understanding
- A smaller, fine-tuned T5-like model outperforms GPT-3 on solving various academic problems with few-shot learning.
- Conditionally Adaptive Multi-Task Learning: Improving Transfer Learning in NLP Using Fewer Parameters & Less Data
- Multi-task fine-tuning is more performant and memory-saving than the conventional per-task fine-tuning.
- Current Limitations of Language Models: What You Need is Retrieval
- Argues how retrieval changes the landscape of LM.
- Scaling Laws for Neural Language Models
Future Trends:
- Increasing model size is important yet not the only factor for performance improvement. In particular, there will be more notable development in augmenting a language model with a retriever (e.g. a la MARGE and knn-LM) for further performance improvement with less supervision.
- GPT-3-like models excel when the target of a given task is not strictly constrained by the input (e.g. open-ended text generation), whereas T5-like models (e.g. MLM) excel otherwise. Unifying these approaches to have the best of both worlds may be an inevitable path.
- For more future trends, details and justifications!
CV
Summary:
- (Efficient) Transformer and scaling are further eroding into CV as with other non-textual domains.
Contents:
- An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
- Transformer performs better than CNN on image classification after pre-training and fine-tuning.
- Generative Pretraining from Pixels
- GPT-2 scale image model learns strong image representations and generation!
- VideoGen: Generative Modeling of Videos using VQ-VAE and Transformers
- SotA video generation
Future Trends:
- The current SotA image generative models (e.g. Sparse Transformer) process each pixel in each layer. Given that nearby pixels are locally strongly correlated, this approach may be redundant and does not scale for images of higher resolution and videos. Since images often contain informative fine details (e.g. symbols), the model has to capture such details. I argue that approaches that resolve this problem will be investigated further, e.g.:
- Some pixel-wise conditional computation methods,
- Generating High Fidelity Images with Subscale Pixel Networks and Multidimensional Upscaling
RL
Summary:
- World model has further improved.
- RL has benefitted from unsupervised pre-training, e.g.:
Contents:
- Mastering Atari with Discrete World Models
- Achieves highly competitive performance on Atari with a small number of steps using world model.
- Unsupervised Active Pre-Training for Reinforcement Learning
- Competitive performance on Atari using only 100k steps by a novel unsupervised active pre-training.
Future Trends:
Unsupervised pre-training for RL, world model, sequence/video modeling and the notion of optimization of data will improve further, both individually and synergically, so that
- model will become larger,
- data efficiency during fine-tuning phase will improve further,
- pre-training with larger generic text, sequence and video datasets will improve the performance further, and
- more diverse tasks will be accommodated as parts of the many fine-tuning tasks.
Optimizer
Summary:
- Learned optimizers and second order optimizers are beginning to outperform the conventional optimizers in a large-scale setting with a substantial margin.
Contents:
- Using a thousand optimization tasks to learn hyperparameter search strategies
- The learned optimizer outperforms the conventional optimizers on large-scale settings.
- Second Order Optimization Made Practical
- The second order optimizer outperforms the conventional optimizers on large-scale settings.
Optimization of Data
What is it?:
Optimization of data, in this linked post listing many relevant papers, refers to the idea of treating RL as (un-)supervised learning on “good data” that the model finds from its interaction with the environment and therefore a joint optimization of the model and the data. In this section, it is argued that this joint optimization also applies to ML as a whole.
Optimization of data for ML in general:
I believe it is natural to argue that the notion of optimization of data is also applicable to ML in general. Let us consider two examples:
- For training any ML model, there are two steps:
- A human constructs the dataset from the environment (e.g. Internet) according to his/her objective. Here, a human provides the full supervision at dataset construction for the model.
- The model is trained on the dataset.
- Some retrieval-based models as MARGE alternately
- train the model to model a segment of text conditioned on its kNN segments (in a certain sense) and
- construct kNN clusters to be used for the step (1) from the dataset (the environment).
Summary:
Thus, ML, including RL, can be broadly thought of as joint optimization of
- model (learning from the data, often (un-)supervisedly) and
- data (obtained and modified by the model from the environment).
- The data a model possesses at a given moment, along with the parameters of the model, can be thought of as the latent variables or the memory of the model.
Conclusion
The recent development can be summarized as approaching problems according to the paradigm of (efficient) Transformer, scaling, pre-training, retrieval and joint optimization of model and data. This trend will continue and simplify ML research toward a unified model.
Acknowledgement: I would like to thank Madison May for his valuable feedbacks and his blog posts that inspired this blog post!
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding

tl;dr:
- GShard enables to scale up multilingual NMT Transformer with Sparsely-Gated MoE beyond 600 billion parameters using automatic sharding.
- Sparsely-Gated MoE reduces performance-computes trade-off dramatically with conditional computation.
- It allows 100x reduction in computes to achieve the performance obtained by the baseline Transformer on multilingual translation.
Details:
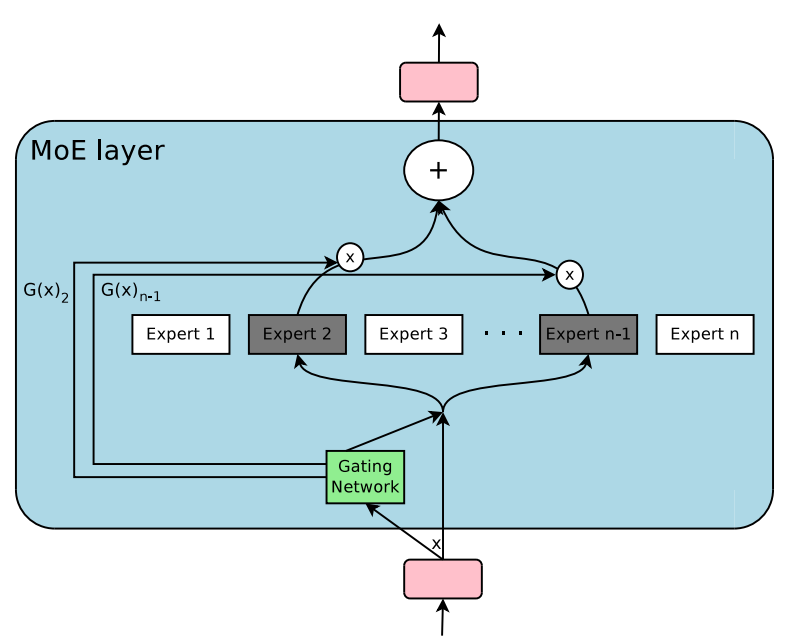
- Sparsely-Gated MoE in this paper is a non-trivial modification of the same component in Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer for Transformer.
- GShard is a module composed of a set of lightweight annotation APIs and an extension to the XLA compiler. It provides an elegant way to express a wide range of parallel computation patterns with minimal changes to the existing model code. The compiler scales with thousands of devices for parallel execution through SPMD.

Comments:
- Though SGMoE would increase GPU memory usage due to its enlarged parameter count, L2L can reduce the GPU memory cost from O(L) to O(1), where L is the number of layers.
- There are several other notable conditional computation approaches for FFN layer, especially Product Key Memory (PKM). SGMoE has many advantages over its competitors, notably its proven scalability and speed. Hence, I recommend SGMoE over its alternatives.
- As discussed in Current Limitations of Language Models: What You Need is Retrieval, SGMoE in place of the feedforward network essentially conditionally computes a single FFN with larger hidden dimension with each of expert being a part of this FFN. In this sense, SGMoE is conditional computations w.r.t. d_ff.
- However, there are many other dimensions, such as depth, that may be conditionally computed for further scaling. For depth in particular, there have been many attempts, but there has been no case of successfully improving the performance-computes trade-off dramatically as SGMoE. Since scaling up a model uniformly tends to perform better, attempts to conditionally compute different dimensions are worthwhile.
- This does not necessarily mean that SGMoE can naively effectively replace components other than FFN, such as the self-attention module.
Relevant links:
- OpenReview
- arXiv
- Tweets:
- Videos:
- Github:
Training Large Neural Networks with Constant Memory using a New Execution Algorithm


tl;dr: Proposes L2L, with which GPU/TPU memory usage becomes constant w.r.t. the number of layers. Able to fit 50B parameters with a single V100 and 500GB CPU memory with no speed loss.
Comments:
- L2L is particularly effective for conditional computation, as the increased number of parameters by CC cost additional GPU memory.
- While L2L can save the GPU memory spent for saving activations, the amount of CPU memory required for this may be beyond one’s budget. In that case, L2L can be combined with gradient checkpointing or RevNet.
Relevant links:
- arXiv
- Tweets:
- Github:
DeepSpeed

tl;dr: A library with various scaling tools, notably the following:
- 3D parallelism: Scaling to trillion-parameter models
- ZeRO-Offload: 10x bigger model training using a single GPU
- Efficient block sparse kernel: Powering 10x longer sequences with 6x faster execution
- 1-bit Adam: 5x less communication and 3.4x faster training
Comments:
- This is probably the best PyTorch library overall for large-scale training with various useful tools.
- ZeRO-Offload seems identical to L2L.
Relevant links:
Pre-training via Paraphrasing

tl;dr: By training a language model and a retriever jointly and modeling a passage from the retrieved similar passages, MARGE achieves:
- Strong zero-shot performance on several tasks, notably BLEU of 35.8 for WMT19 EnDe, with minimal inductive bias.
- Strong performance on various tasks after fine-tuning as a potential pre-training alternative to MLM.
Details:

- MARGE self-supervises the reconstruction of target text by retrieving a set of related texts (in many languages) and conditioning on them to maximize the likelihood of generating the original.
- MARGE adds attention bias such that the attention between the samples with closer embeddings have larger weights, which allows the joint training of the embedder (retriever) and the language model.
Comments:
- While MARGE slightly lags behind BERT on monolingual NLU tasks, there is a substantial potential of MARGE-like pre-training for a better alternative to the existing pre-training methods.
- Architecture-wise, FiD is similar to MARGE, though it does not have a similar embedding bias. Examples of joint training of a retriever and a language model includes REALM, CRISS and KIF.
- This paper devotes a section to discuss the significance and implications of MARGE, including its potential application to improve GPT-3-like models.
Relevant links:
- arXiv
- Tweets:
Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval

tl;dr: Achieves the SOTA performance-computes trade-off in multi-hop open-domain QA (better than Fusion-in-Decoder). Best published accuracy on HotpotQA with 10x faster inference.
Details:


- While RAG and FiD have shown strong improvements over extractive models on single-hop datasets such as NaturalQuestions, they do not show an advantage in the multi-hop case. Despite having twice as many parameters as ELECTRA, FiD fails to outperform it using the same amount of context (top 50).
Relevant links:
- arXiv
- OpenReview
- Tweets:
Cross-lingual Retrieval for Iterative Self-Supervised Training

tl;dr: Achieves SotA (unsupervised NMT) BLEU on 9 language directions (+2.4 BLEU on avg.) without back-translation by retrieving the target with faiss.

Comments:
- This work is similar to that of other models jointly training a retriever and a language model, such as MARGE. They tend to be a variant of the following and show the SotA performance in their respective setting:
- Essentially, it retrieves the kNN samples from a given query and models the query conditioned on the retrieved samples.
- After a certain number of iterations, it evaluates the embeddings of each sample and identifies the kNNs of each sample (e.g. with faiss).
- One can repeat this process from the beginning using this newly updated kNN relationship.
Relevant links:
Long Range Arena: A Benchmark for Efficient Transformers

tl;dr: Various Transformer variants are benchmarked over various tasks. Performance-computes trade-off for each model is obtained as above.

Details:
- BigBird and Performer may have the best trade-off overall, the latter of which also excels at textual tasks in particular.
- Predictably, Sparse Transformer, the model with explicit inductive bias of images, outperforms other models at image modeling with a substantial margin.
Comments:
- Speed is subject to implementation, so the result concerning speed may change, especially if we change the batch length. However, this result offers a good coarse picture.
- Routing Transformer is not considered despite its superior performance in text.
- The performance of Performer may be underestimated, since they use FAVOR instead of more performant FAVOR+.
- There are some notable related surveys on efficient attention:
Relevant links:
Rethinking Attention with Performers

tl;dr: O(N)-Transformer with competitive performance that approximates regular attention with provable accuracy. Performer outperforms Reformer and Linformer.
Comments:
- As discussed in Long Range Arena: A Benchmark for Efficient Transformers, Performer is likely to have the best performance-computes trade-off overall, possibly excluding Routing Transformer, which was not compared. Please refer to this paper for comprehensive performance evaluation (note: their version of Performer is not up-to-date).
Relevant links:
Scaling Laws for Neural Language Models

tl;dr:
- The loss of LM scales as a power-law with model size (N), dataset size (D), and the amount of computes spent for training (C) up to seven order of magnitudes.
- They find the optimal allocation of a fixed compute budget to maximize the performance.
- Most additional computes need to be spent for enlarging the model size.
Details:

- Dataset size needs to be large enough that the same sample is never reused.
- This power law translates to the scaling depicted as in the following figure that shows most computes should go to model enlargement:

Comments:
- Since the exponent for serial step count is almost zero, one can consider this as a constant number. According to the author, setting S = 2S_min ~ 10k and B = B_crit is an empirically reasonable choice.
- -> This implies that 10k iterations are all you need!
- Since the exponent for batch size or dataset size is somewhat small, we can expect that even the most performant models would require not much larger than several millions of batch size or 10B tokens of dataset size, respectively.
- For batch size, this implies that the upper bound for a reasonable batch size is not particularly large.
- For dataset size, this somewhat matches with the fact that humans would not process much larger than several billions of tokens in their lifetime.
Relevant links:
Learning to Summarize From Human Feedback

tl;dr: Achieves super human-level summarization on TL;DR dataset by training a reward function on human feedback and fine-tuning a pre-trained generator (GPT-3 variants) with PPO.

Comments:
- One can attempt the same approach to any data that can be ranked with reasonable cost (e.g. by human annotations). In this sense, the generality of this method is quite appealing and remarkable.
- This work is also notable for showing that fine-tuning an unsupervisedly pre-trained model with a RL objective produces competitive results.
Relevant links:
Measuring Massive Multitask Language Understanding

tl;dr: A smaller, fine-tuned T5-like model (UnifiedQA) outperforms GPT-3 on solving various academic problems, ranging from elementary mathematics to US history, with few-shot learning.
Details:

- UnifiedQA uses the T5 text-to-text backbone and is fine-tuned on a certain QA dataset. Then, it is evaluated with few-shot learning without further fine-tuning specific to the domain of the problem in order to remove the need for a large fine-tuning set specifically for a narrow domain, whose availability cannot be assumed in general (relevant section).
Relevant links:
- OpenReview
- arXiv
- Tweets:
Conditionally Adaptive Multi-Task Learning: Improving Transfer Learning in NLP Using Fewer Parameters & Less Data

tl;dr: Proposes a multi-task fine-tuning that is more performant and memory-saving than the conventional per-task fine-tuning.
Details:
- Per-task fine-tuning of a model produces a set of parameters specifically for each task, which means fine-tuning individually for each task costs memory for the set of parameters each task produces.

- Notably, the proposed method outperforms T5 by 6 points on Super-GLUE by using one-fourth of parameter count.
Comments:
- The following papers also propose multi-task fine-tuning:
- HyperGrid Transformers seem to not require a per-task decoder, which may be more desirable for extension.
Relevant links:
Current Limitations of Language Models: What You Need is Retrieval

tl;dr:
- Classifies and analyzes LM approaches as efficient attention, recurrence and scaling up model size.
- There are some limitations on these approaches for improvement.
- Retrieval should solve many of them.
- Speculates on jointly training GPT-3 and a retriever a la MARGE for further improvement.
Details:
- Efficient attention and recurrence do not improve the prediction of the first ∼ 10^3 tokens, which becomes a bottleneck.
- Scaling up a model size (e.g. efficiently with conditional computation) still results in poor performance scaling for some tasks (e.g. GPT-3 vs FiD or iPET).
- The usual assumption of the availability of a large training dataset (e.g. for fine-tuning) that is very similar to the test dataset is unrealistic, which needs to be re-examined.
- MLM and GPT-2-like models excel at different tasks, which means that there needs a single model to unify these.

- The conventional causal modeling (left) vs. the speculated modified MARGE (right). If the tokens in last two blocks are to be predicted (red), the attention is paid to the past tokens in the red region and the tokens in the context (green). The modified MARGE reads the immediate context (purple) to find the relevant parts across the dataset and the past of the current sample in order to use them as a context.
- Essentially, the right approach predicts by efficiently sparsely referencing to the indefinite past as well as cross-referencing to other samples.
Comments:
- Admittedly, this paper may not be considered as a notable work comparable to other works listed in this blog post. However, as the author of this paper, I believe it is noteworthy and relevant for this blog post as providing some details for my view of the future trends of LM.
Relevant links:
- arXiv
- Tweets:
More Future Trends of NLP
This section expands and elaborates what is described in Future Trends of NLP section of Table of Contents.
- The usual assumption of the availability of a large training dataset (e.g. for fine-tuning) that is very similar to the test dataset is unrealistic, which needs to be resolved.
- Measuring Massive Multitask Language Understanding avoids this problem with a large, general fine-tuning dataset and more specialized few-shot learning samples as an alternative.
- Few-shot learning samples may also be replaced with an unsupervisedly retrieved samples to minimize the assumption further.
- Retrieval-augmented LM may be able to not only attend to any training sample but also the (indefinite) past in a similar way by segmenting each sample into embeddable segments, from which we can find the relevant segments with kNN search.
- For more details and justifications
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale

tl;dr: When pre-trained and transferred to CV tasks, Vision Transformer, needing minimal amount of inductive bias only at preprocessing, attains excellent results compared to SOTA CNNs while requiring much fewer computational resources to train.

Comments:
- Notable differences between this paper and other papers applying self-attention to CV tasks:
- The model they use is essentially the vanilla Transformer with no 2D inductive bias except at the beginning.
- Suggests the possibility of seamless unification of architecture over various modalities.
- They perform larger-scale evaluation with focus on performance-computes trade-off.
- The model they use is essentially the vanilla Transformer with no 2D inductive bias except at the beginning.
- This work further motivates for Transformer-ization of research of CV and other modalities.
- Unification of architecture across various modalities would simplify and unify ML research.
- The poor performance-computes trade-off of iGPT relative to the SotA CNN models in some tasks may be easily fixed.
Relevant links:
- OpenReview
- Videos:
Generative Pretraining from Pixels


tl;dr: GPT-2 scale image model learns strong image representations as measured by linear probing, fine-tuning, and low-data classification despite having minimal 2D inductive bias and low-resolution ImageNet without label. The generated images are stunning!
Details:

- Pre-trains Sparse Transformer of varying sizes with low-resolution ImageNet with the ordinary causal modeling or BERT modeling and then fine-tune or linear-probe the model for classification.
Comments:
- One significance of this paper is that it shows a robust scaling of the loss w.r.t. the size of the generative image model, which had not been performed before even if it was predictable.
- One of the causes of poor performance of iGPT relative to Vision Transformer is presumably that the former is trained unsupervisedly, whereas the latter is trained supervisedly with essentially the same task for both pre-training and fine-tuning (classification). If a down-streaming task differs from the pre-training, the performance difference may diminish.
Relevant links:
VideoGen: Generative Modeling of Videos using VQ-VAE and Transformers

tl;dr: VQ-VAE-based, GPT-like model with 3D convolutions and axial self-attention improves the SotA bits/dim on BAIR dataset from 3.94 (Axial Attention) to 3.62.
Comments:
- There have been many other competitive video modeling papers submitted to ICLR 2021, notably:
Relevant links:
Mastering Atari with Discrete World Models

Components of Dreamer. Taken from DreamerV1 paper (Hafner, 2019)
tl;dr: Proposes DreamerV2, the first agent that achieves human-level performance on the Atari benchmark of 55 tasks by learning behaviors inside a separately trained world model.

Details:
- MuZero performs better for the same number of environment frames, but its MCTS makes it harder to parallelize. The advanced planning components of MuZero are complementary and could be applied to the accurate world models learned by DreamerV2.
- The above figure, in fact, under-estimates the dominance of DreamerV2 in terms of a more robust measurement of performance. Please refer to the paper for further details on this.
Relevant links:
- arXiv (DreamerV2); arXiv (DreamerV1)
- OpenReview
- Tweets:
- Github:
- DreamerV1 (needs to be modified for DreamerV2 as described in the appendix)
Unsupervised Active Pre-Training for Reinforcement Learning

tl;dr: Highly competitive performance compared to canonical RL algorithms is achieved using only 100k steps on Atari by a novel unsupervised active pre-training.

Details:
- APT alternates between contrastive learning on data collected by the agent and RL optimization to maximize particle based entropy. After pre-training, the encoder f_θ and the RL policy initialization can be fine-tuned for different downstream tasks to maximize task-specific reward.
Relevant links:
Using a thousand optimization tasks to learn hyperparameter search strategies

tl;dr: An optimizer learned from a dataset of hyperparameters of a thousand tasks leads to a substantial improvement over various tasks, including large-scale problems such as LM1B and ImageNet.
Details:


Comments:
- The following is a relevant paper:
- Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves
- Learned optimizer that generalizes better to unseen tasks and enables automatic regularization.
- Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves
Relevant links:
Second Order Optimization Made Practical

tl;dr:
- Presents a scalable implementation of a second-order optimizer (Shampoo) that defeats the first order baselines on large-scale problems in terms of wall-clock time.
- This is the first implementation of 2nd order optimizer that outperforms Adam on large-scale NMT in terms of wall-clock time (40% reduction).

Relevant links:
- OpenReview (with a different title)
- arXiv
- Tweets:

Leave a comment